The Context Stack
Give AI the Context It Needs to Work Like a Colleague

TLDR: A good prompt is necessary but not sufficient. AI also needs to understand who you are, where you sit institutionally, and what you are working with right now. The Context Stack is a five-layer architecture that bridges your data foundation to actionable AI output, applicable across any function in a university research enterprise.
Listen to a 90 Second overview below or click here for 30 minute deep-dive
Overview
A well-structured file system establishes the substrate: durable, portable, AI-readable data. But a well-structured file handed to an AI cold still produces generic output. The model lacks the interpretive layer required to reason about your work in context.
That gap has a structure. Think of it as a stack. Each layer is a prerequisite for the one next to it. Skipping layers does not accelerate output, it degrades quality in ways that are easy to misdiagnose as model limitations.
The Layers
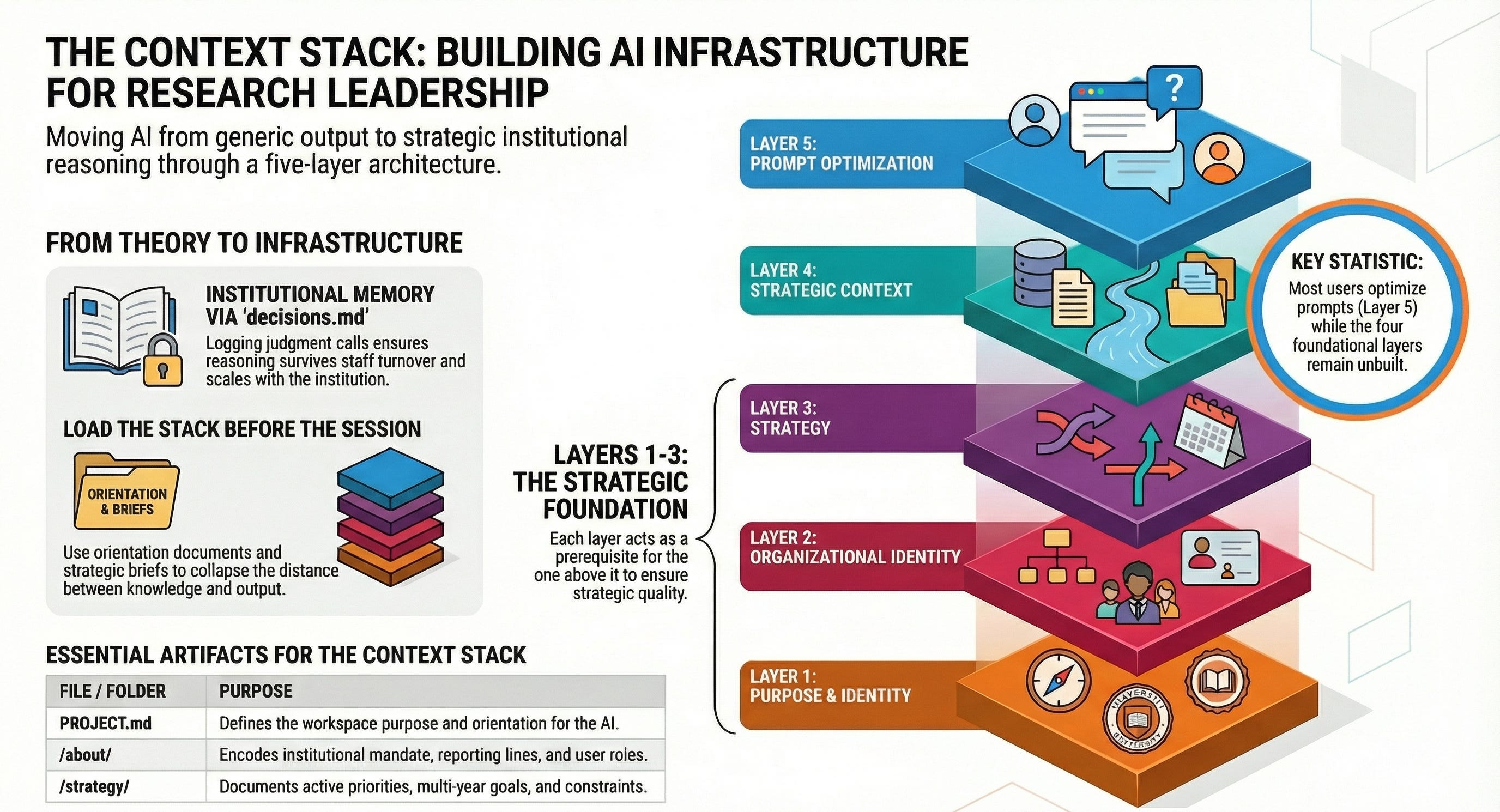
Layer 1: Purpose
Define what this workspace is for. Strategic planning, faculty development, research development, compliance, institutional reporting: each carries different reasoning requirements. Without an explicit purpose definition, the model defaults to generic reasoning. This is the load-bearing layer everything else depends on.
Layer 2: Organizational Identity
Who is asking, in what role, within what institutional structure? This encodes your unit’s mandate, reporting relationships, and key stakeholders, whether that is a VPR, provost, faculty governance body, or federal sponsor. It allows the model to interpret the same question differently depending on where it is being asked from.
Layer 3: Strategy
What direction is your unit moving? Current priorities, multi-year initiatives, known constraints and competing pressures. Without this layer, the model evaluates options against generalized best practices rather than your actual criteria. This is what separates strategic reasoning from informed noise.
Layer 4: Current Data
Live institutional information: active initiatives, workforce data, benchmarks, draft documents, survey results, budget snapshots. This is where FILE pays off directly because your data is already in a format the model can parse. At this layer, AI shifts from general advisor to analytical partner operating on your actual situation.
Layer 5: The Query
Only here does prompt quality become the primary performance variable. A precise query on a fully loaded stack produces fundamentally different output than the same query on an empty context. Most users are optimizing this layer while the four beneath it remain unbuilt.
What This Looks Like in Practice
Note: The following examples are AI-generated illustrations.
The structure is identical across every role and function. The foundation layer, identity, strategy, data, and work are constant. Only the content inside each file changes. Three examples illustrate the point.
A HERD Survey Analyst
The decisions.md file carries particular value here. HERD is full of judgment calls: how you classify interdisciplinary expenditures, how you handle cost sharing, how you aggregate agency codes. Logging those decisions means next year’s submission starts with institutional memory already loaded rather than rebuilt from scratch.
/division-research-innovation/
│
├── PROJECT.md ← Purpose: HERD survey
│ preparation and submission
├── /about/
│ ├── about-business.md ← DRI mandate, NSF relationship,
│ │ survey obligations
│ └── about-you.md ← Your role, data access,
│ key contacts
├── /strategy/
│ └── strategy.md ← NACUBO mapping, F&A methodology,
│ prior year decisions
├── /data/
│ └── current-data.md ← Expenditures by source, discipline
│ codes, peer benchmarks
└── /work/
├── /herd-2026/
│ ├── project.md ← Scope, timeline, contacts
│ ├── tasks.md ← Open items, deadlines
│ ├── decisions.md ← Classification calls, edge cases,
│ │ methodology changes
│ └── log.md ← Anomalies, coordinator updates
└── herd-status.md ← AI-generated readiness brief
A VP of Faculty Affairs
/faculty-affairs-vp/
│
├── PROJECT.md ← Purpose, orientation
├── /identity/
│ ├── office-overview.md ← Mandate, scope, authority
│ ├── stakeholders.md ← Provost, deans, faculty senate
│ └── governance.md ← Policy ownership, committees
├── /strategy/
│ ├── priorities-2026.md ← Retention, equity goals
│ ├── initiatives.md ← DEI programs, policy reform
│ └── constraints.md ← Budget limits, union agreements
├── /data/
│ ├── faculty-demographics.md
│ ├── promotion-pipeline.md
│ ├── retention-risk.md
│ └── compensation-benchmarks.md
└── /work/
├── /policy-review-2026/
├── /faculty-leadership-program/
├── /promotion-cycle-2026/
└── weekly-briefing.md
A Director of a Newly Formed Industry Partnership Hub
A newly formed hub will make a lot of foundational calls early: what sectors to prioritize, how to structure tiered partnerships, what a university brings versus what an industry partner expects. Logging those decisions in decisions.md means institutional memory survives staff turnover and the reasoning behind early choices stays accessible as the hub scales.
/innovation-hub/
│
├── PROJECT.md ← Purpose: establish and operate
│ a new collaboration and industry
│ partnership hub
├── /about/
│ ├── about-business.md ← Hub mandate, university backing,
│ │ founding charter, success metrics
│ └── about-you.md ← Your role, decision authority,
│ key relationships
├── /strategy/
│ └── strategy.md ← Partnership model, target sectors,
│ engagement pipeline, revenue goals
├── /data/
│ └── current-data.md ← Active partner conversations,
│ MOU status, space utilization,
│ pipeline metrics, peer benchmarks
└── /work/
├── /partner-pipeline/
│ ├── project.md
│ ├── tasks.md
│ ├── decisions.md ← Partnership terms, exclusivity
│ │ calls, tier structure decisions
│ └── log.md
├── /hub-launch/
│ └── project.md
├── /programming/
│ └── project.md
└── weekly-briefing.md ← AI-generated pipeline summary
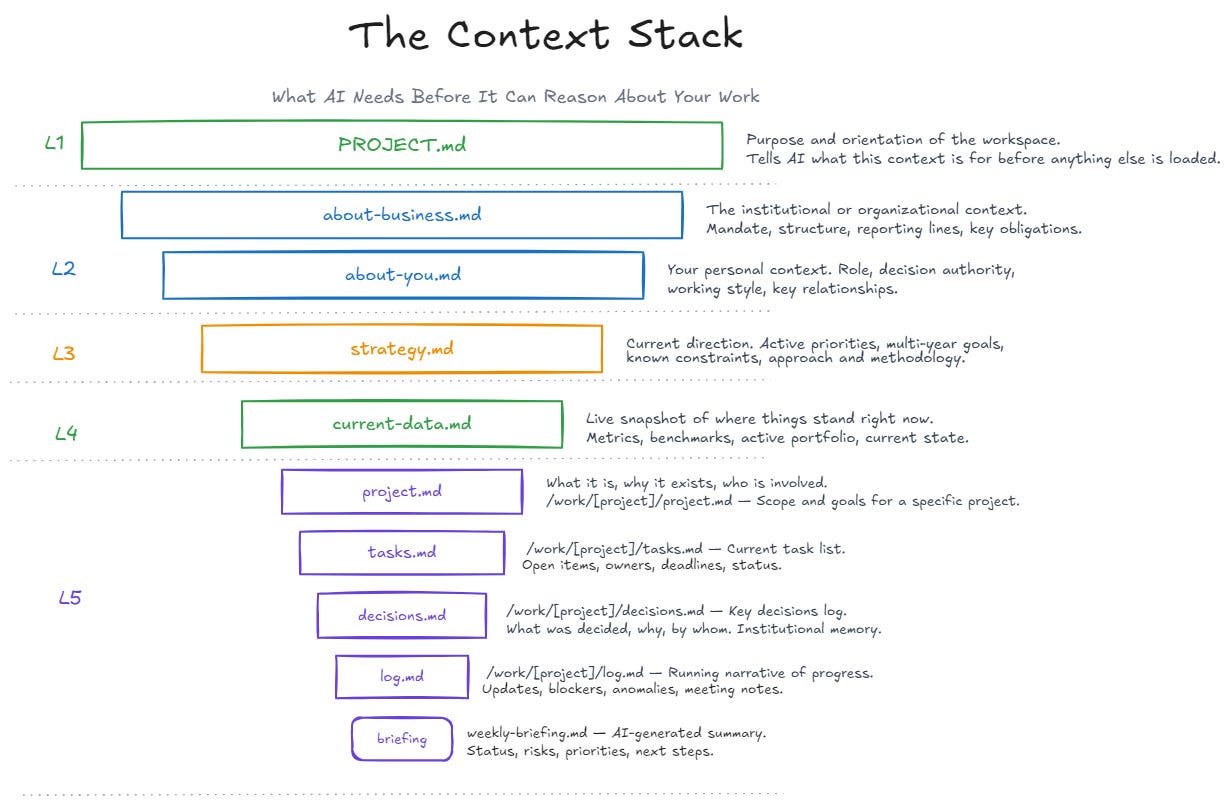
File Reference
These are the core files you need for each project, preferably as Markdown (.md) files.
PROJECT.md -Purpose and orientation of the workspace. Tells the AI what this context is for before anything else is loaded.
about-business.md - The institutional or organizational context. Mandate, structure, reporting lines, key obligations.
about-you.md - Your personal context. Role, decision authority, working style, key relationships.
strategy.md -Current direction. Active priorities, multi-year goals, known constraints, approach and methodology.
current-data.md - Live snapshot of where things stand right now. Metrics, benchmarks, active portfolio, current state.
project.md - Scope and goals for a specific project. What it is, why it exists, who is involved.
tasks.md -Current task list. Open items, owners, deadlines, status.
decisions.md - Log of key decisions made. What was decided, why, and by whom. Institutional memory.
log.md - Running narrative of progress. Updates, blockers, anomalies, meeting notes.
weekly-briefing.md - AI-generated summary pulled from the work folder. Status, risks, priorities, next steps.
Drop these files into your authorized AI chatbot of choice and you instantly give it institutional memory and operational context. No lengthy onboarding, no re-explaining your situation. The stack does that work for you.
The Operational Implication
The Context Stack is not a one-time setup. It is a design principle for how you can move to an AI-First workflow. Central to that workflow is the concept of a context artifact: any pre-built, reusable document that AI can load and reason from.
Drop these files in you AI chatbot of choice to start using this workflow
Orientation documents, strategic briefs, and current-state snapshots are all context artifacts. Build them once, and they eliminate the need to re-explain your situation at the start of every session. Loading them collapses the distance between institutional knowledge and AI output.
The Context Stack tells AI what to do with it.
The units that extract durable value from AI will not be those with the best prompts. They will be the ones that treat institutional context as infrastructure.
